Dokumentacja użytkownika GUS import
Dokumentacja użytkownika Wersja 1.0
Rozdział 1. Informacje o dokumencie
Niniejszy dokument zawiera informacje na temat modułu GUS import rozszerzającego moduł Baza CRM dostępnego na Platformie Analitycznej Hyperflow znajdującej się pod adresem https://hyperflow.eu/client/. Niniejszy dokument jest dokumentacją użytkownika modułu GUS import w wersji 1.0.
Moduł GUS import nie działa samodzielnie. Informacje i zdjęcia zawarte w dokumentacji przedstawiają moduł GUS import osadzony w podstawowym modułe Baza CRM. W przypadku posiadania wyłącznie podstawowego modułu Baza CRM, funkcjonalności GUS import nie są dostępne. Aby zapoznać się z podstawowymi informacjami na temat modułu podstawowego zapraszamy do dokumentacji modułu Baza CRM.
Rozdział 2. Możliwości modułu GUS import
Moduł GUS import służy do weryfikacji i analizy danych kontrahentów. Jest niezbędny do wykonywania automatycznych analiz i weryfikacji danych w ramach modułu Baza CRM.
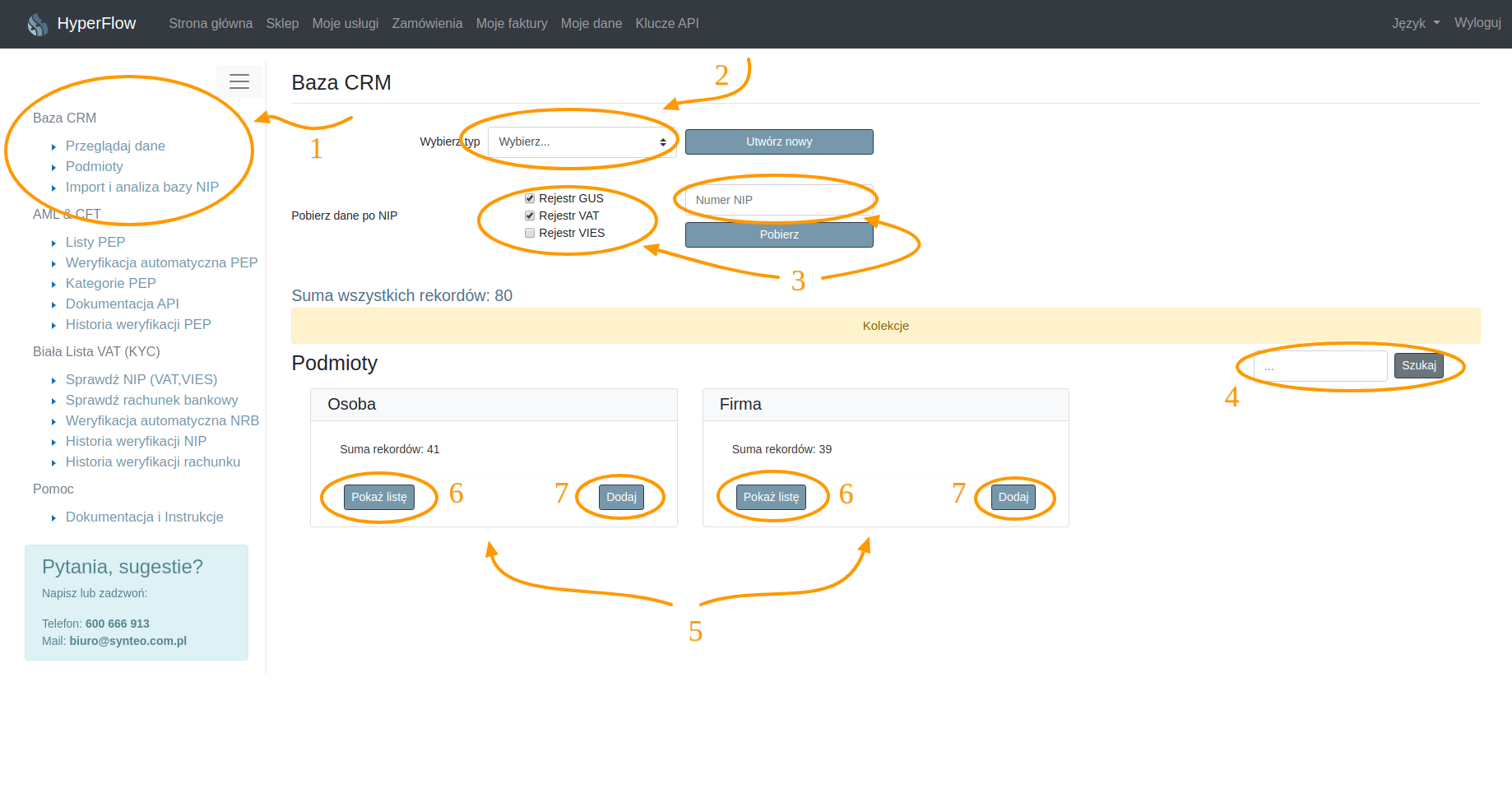
GUS import dostarcza widget w celu pobierania danych z rejestrów (rysunek 2.1 punkt 3) oraz Import i analizę bazy NIP – funkcjonalność dostępna z poziomu menu bocznego (punkt 1 rysunku opcja trzecia).
- Przeglądaj dane
- Podmioty
- Import i analiza bazy NIP (moduł GUS import)
W ramach pakietu demo otrzymują Państwo darmowy pakiet 5 zapytań w celu przetestowania usługi.
2.1. Widget pobierania danych z rejestrów
Rysunek 2.1 przedstawia główny widok podstawowego modułu Baza CRM z modułem GUS import. Punkt 3 przedstawia widget pobierania danych z rejestrów GUS, VAT i VIES:
- Rejestr GUS: sprawdza czy podany przez klienta numer NIP jest poprawny i czy firma o podanym numerze istnieje. Źródłem danych jest Główny Urząd Statystyczny.
- Rejestr VAT: sprawdza czy firma o podanym numerze NIP jest zarejestrowana jako podatnik VAT na Białej Liście VAT. Źródłem danych jest rejestr prowadzony przez KAS (Krajowa Administracja Skarbowa) a metodą dostępu – usługa API KAS.
- Rejestr VIES: sprawdza aktywność numeru VAT UE. W odpowiedzi otrzymujemy informację na potrzeby transakcji transgranicznych w obrębie UE.
Aby pobrać dane z rejestrów, należy wybrać – zaznaczyć checkbox przy pożądanych rejestrach, wprowadzić numer NIP i zatwierdzić wybór klawiszem enter lub kliknąć przycisk “Pobierz”.
Wprowadzone dane mogą zawierać myślniki lub/ i spacje.
Jeżeli numer został wprowadzony niepoprawnie (jest za krótki, za długi, lub niepoprawnie skonstruowany) w odpowiedzi otrzymamy informację “Niepoprawny NIP”.
Jeżeli wprowadzony numer jest poprawny jednak nie jest przypisany do żadnej działalności, w odpowiedzi wyświetli nam się pusty formularz dla firmy jedynie z wprowadzonym numerem NIP. Oznacza to, że numer jest prawidłowo wygenerowany, ale nie został znaleziony w rejestrach – na przykład firma może być dopiero w trakcie rejestracji. Te dane jednak wystarczają by zapisać formularz i monitorować kontrahenta.
Jeżeli numer jest wprowadzony poprawnie i istnieje firma zarejestrowana pod tym numerem, w odpowiedzi wyświetli się formularz z wprowadzonymi danymi z rejestrów. Formularz można uzupełnić o własne dane np kategorię podmiotu (Dostawca, Odbiorca), a następnie zapisać w bazie klikając przycisk “Zapisz”.
Formularze szczegółowo zostały opisane w dokumentacji modułu podstawowego Baza CRM.
Rozdział 3. Import i analiza bazy NIP
Import i analiza bazy NIP pozwala na automatyczne monitorowanie danych kontrahentów i ich zmian w bazie REGON. Analiza odbywa się na podstawie numeru NIP.
3.1. Do czego służy import i analiza bazy NIP?
Automatyczna analiza NIP pozwala na regularne, automatyczne weryfikowanie kontrahentów w bazie REGON. Usługa ta pozwala całkowicie pozbyć się kłopotów związanych z weryfikacją zmian danych takich jak zmiana adresu czy zawieszenie działalności przez kontrahenta. Aby skonfigurować automatyczną analizę numerów NIP kontrahentów należy:
- aktywować automatyczną analizę,
- skonfigurować automatyczne pobieranie danych do analizy lub wprowadzić te dane ręcznie.
3.2. Ustawienia automatycznej weryfikacji.
Główny panel automatycznej weryfikacji przedstawia rysunek nr 3.1.
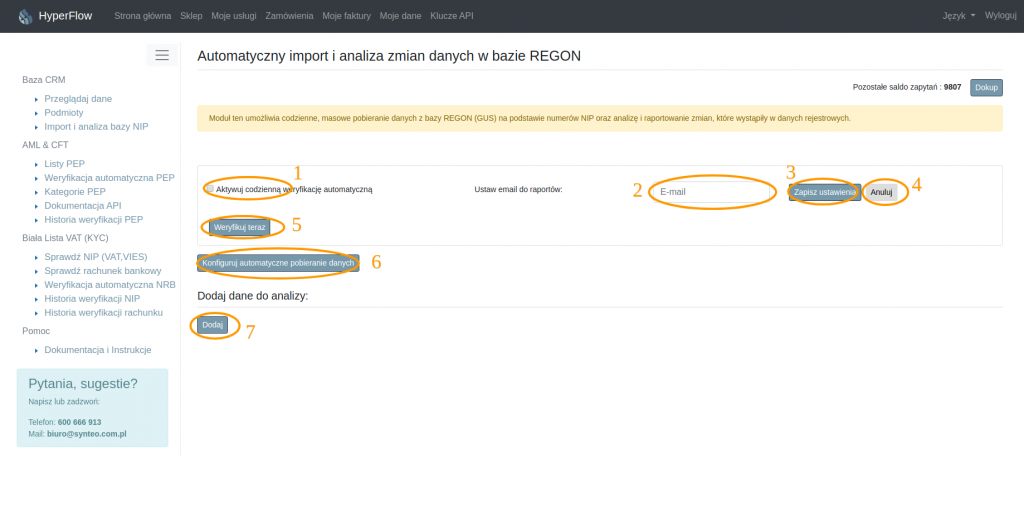
Na rysunku powyżej punktem 1 został oznaczony checkbox automatycznej weryfikacji. Zaznaczenie tej opcji oraz zapisanie ustawień (punkt 3 rysunku) powoduje cykliczne, codzienne wykonanie weryfikacji wprowadzonych do automatycznej analizy danych w rejestrze. Punkt 2 na rysunku pozwala na wprowadzenie adresu email, na który będą wysyłane raporty, nie jest on jednak konieczny. Wyniki analizy będą widoczne w panelu analizy. Po dokonaniu potrzebnych zmian zawsze należy zatwierdzić wprowadzone dane klikając “Zapisz ustawienia” (punkt 3). Aby przerwać modyfikację ustawień należy kliknąć “Anuluj” (pkt 4).
Punkt 6 rysunku 3.1 wskazuje na konfigurację automatu do pobierania danych. Szerzej o tej funkcji przeczytasz w następnym punkcie dokumentacji. Punkt 7 to przycisk dodaj. Jest to opcja dostępna tylko w przypadku braku automatycznej konfiguracji pobierania danych i pozwala na ręczne wprowadzanie danych do analizy.
3.2.1. Uruchomienie analizy na żądanie
Klawisz “Weryfikuj teraz” służy do jednorazowego uruchomienia weryfikacji danych zawartych w buforze – na żądanie. Po wprowadzeniu danych lub skonfigurowaniu ich pobierania, można wykonać analizy na żądanie, nie czekając na automat, który przeprowadza analizy w nocy.
3.3. Konfiguracja pobierania danych.
Po kliknięciu klawisza “Konfiguruj automatyczne pobieranie danych” rozwija się panel konfiguratora automatu pobierania danych – rysunek 3.2. Do wyboru mamy trzy opcje. Każdorazowa zmiana ustawień konfiguratora musi być zatwierdzona klawiszem “Zapisz”. Aby przywrócić/wycofać wprowadzanie zmian należy kliknąć przycisk “Anuluj”.
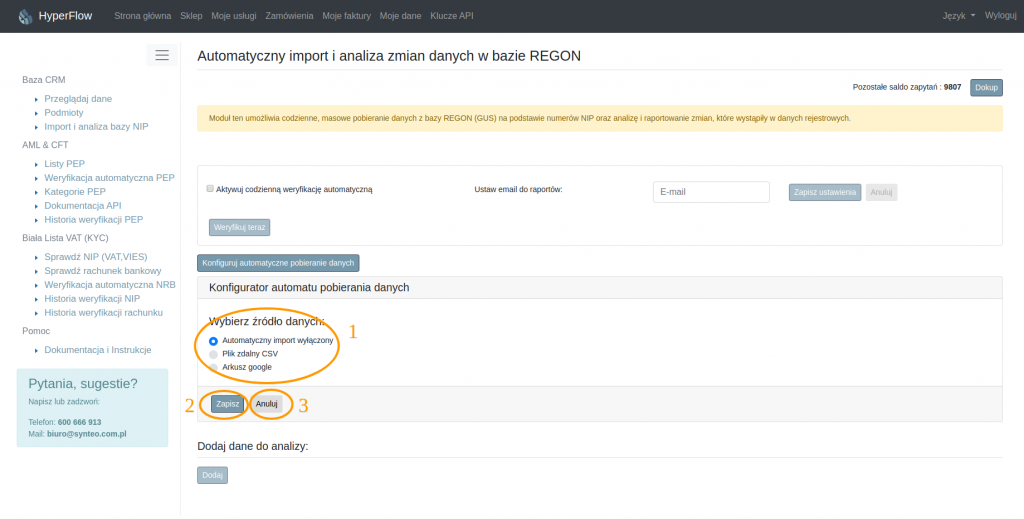
3.3.1 Automatyczny import wyłączony
Oznacza to, że dane do analizy nie będą pobierane z zewnętrznych źródeł, a analizie (jeżeli automat opisany w punkcie 3.2 dokumentacji jest włączony) poddane będą tylko dane wcześniej wprowadzone do analizy i znajdujące się w bazie.
3.3.2 Plik zdalny CSV
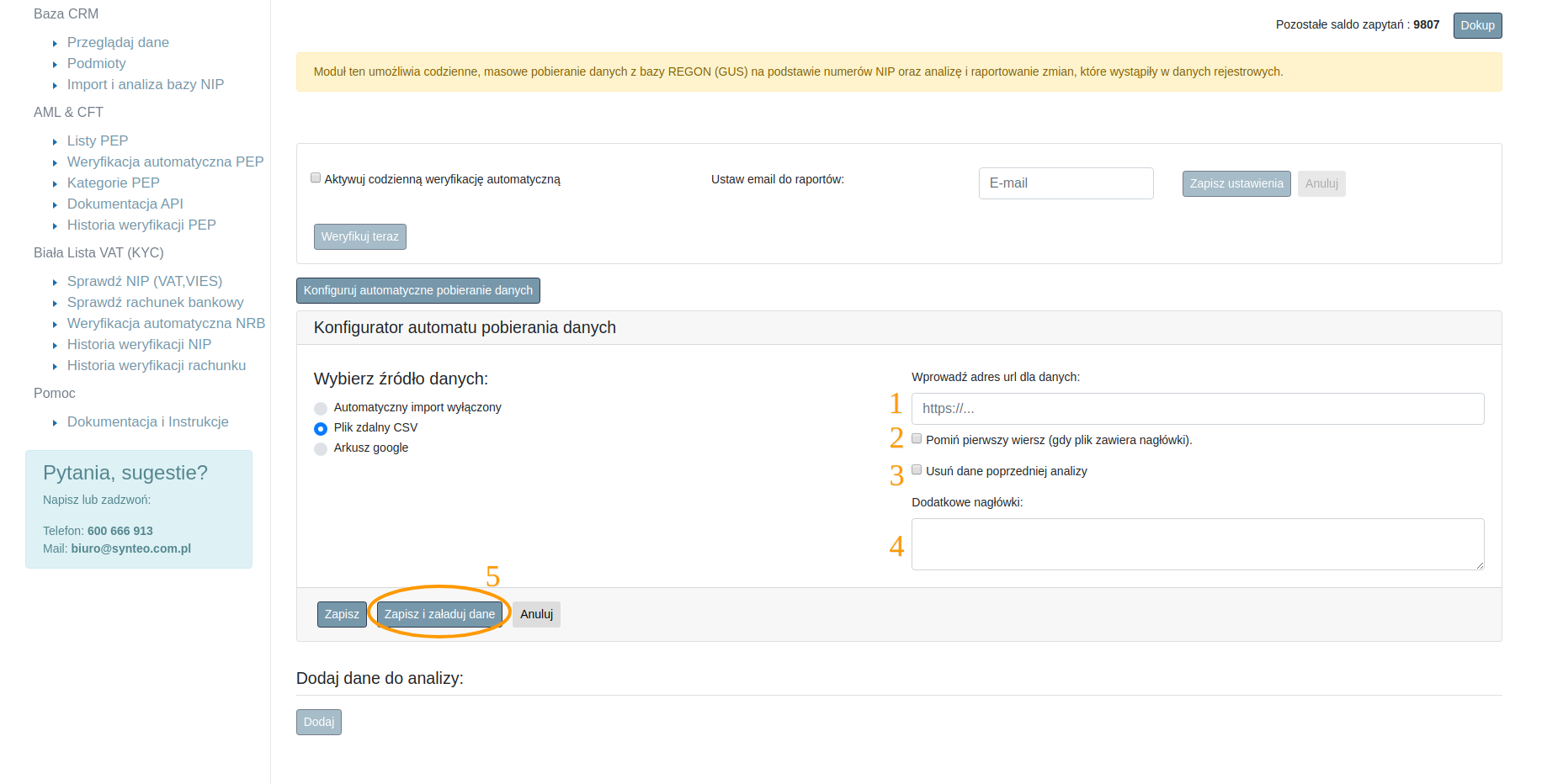
Zaznaczenie opcji “Plik zdalny CSV” pozwala na wczytanie danych z pliku. W tym przypadku należy podać ścieżkę dostępu do pliku zdalnego (na przykład na innym serwerze) w punkcie 1 rys 3.3.
Punkt 2 rysunku 3.3 należy zaznaczyć jeżeli plik zawiera wiersz nagłówka (wiersz z opisem zawartości kolumn).
Punkt 3 należy zaznaczyć, jeżeli sprawdzane dane każdorazowo mają być pobierane z pliku. Ta opcja jest przydatna, gdy na bieżąco uzupełniamy listę kontrahentów w pliku – czyli dodajemy i usuwamy kontrahentów, modyfikujemy ich dane w pliku. Wtedy każdorazowa weryfikacja pobierze nowe dane do weryfikacji, a stare dane nie będą weryfikowane. Pozostawienie niezaznaczonej opcji skutkuje pozostawieniem danych z poprzedniej analizy do weryfikacji razem z danymi z bieżącego pliku.
Punkt 4 pozwala na wprowadzenie dodatkowych nagłówków HTTP potrzebnych do odczytania pliku (np autoryzacja HTTP Basic czy tokeny).
3.3.3 Arkusz google
Konfigurator dla arkusza google spreadsheets wygląda bardzo podobnie do omówionej wyżej konfiguracji dla zdalnego pliku CSV.
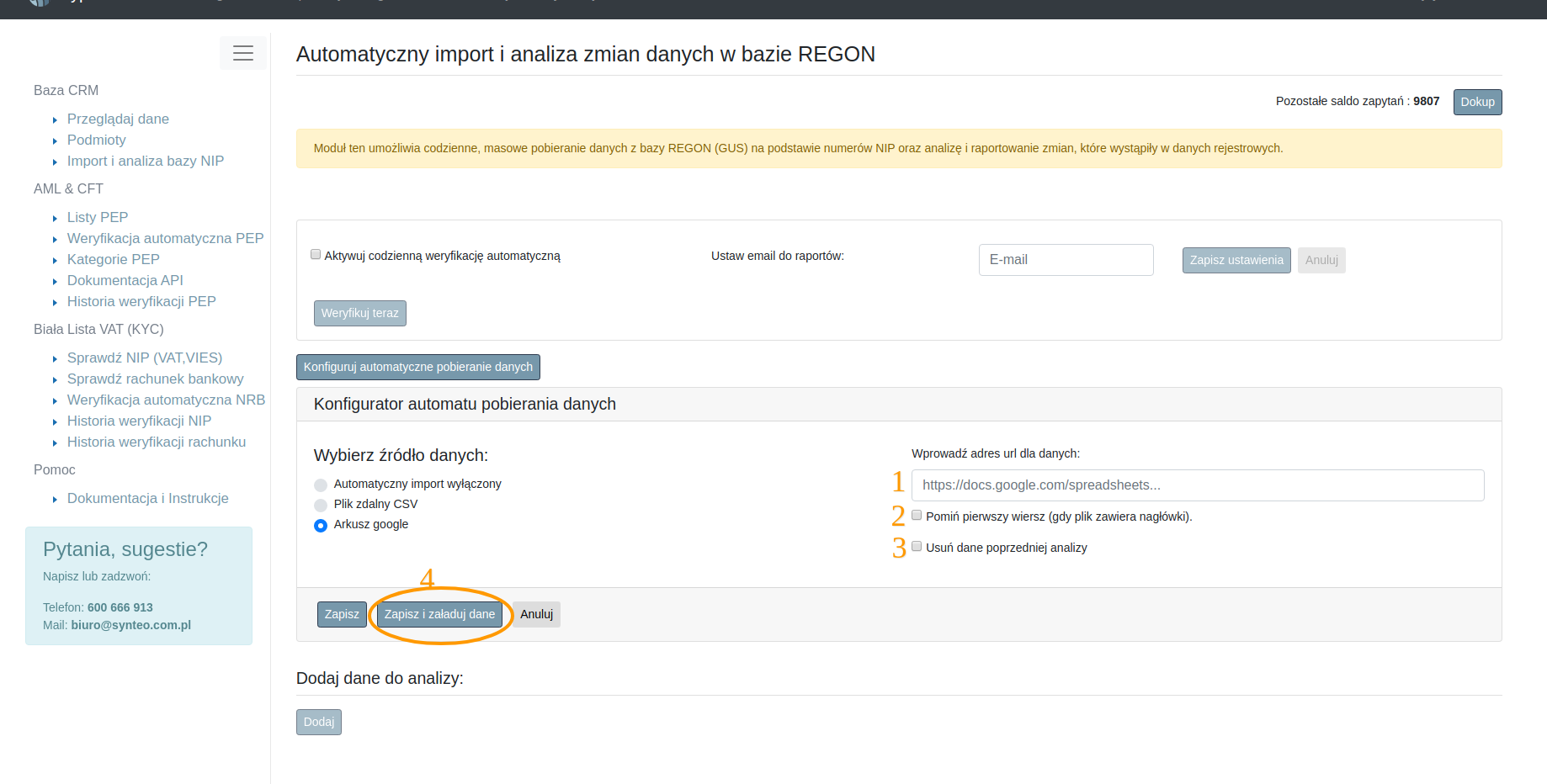
Punkt 1 na rysunku 3.4 to miejsce na ścieżkę dostępu dla pliku google. Zaznaczenie opcji opisanej punktem 2 skutkuje pominięciem pierwszego wiersza pliku. Zaznaczenie opcji z punktu 3 skutkuje usunięciem wprowadzonych wcześniej danych do analizy.
Aby skorzystać ze źródła danych w postaci arkusza google należy go najpierw przygotować i udostępnić w trybie Shareable by Link.
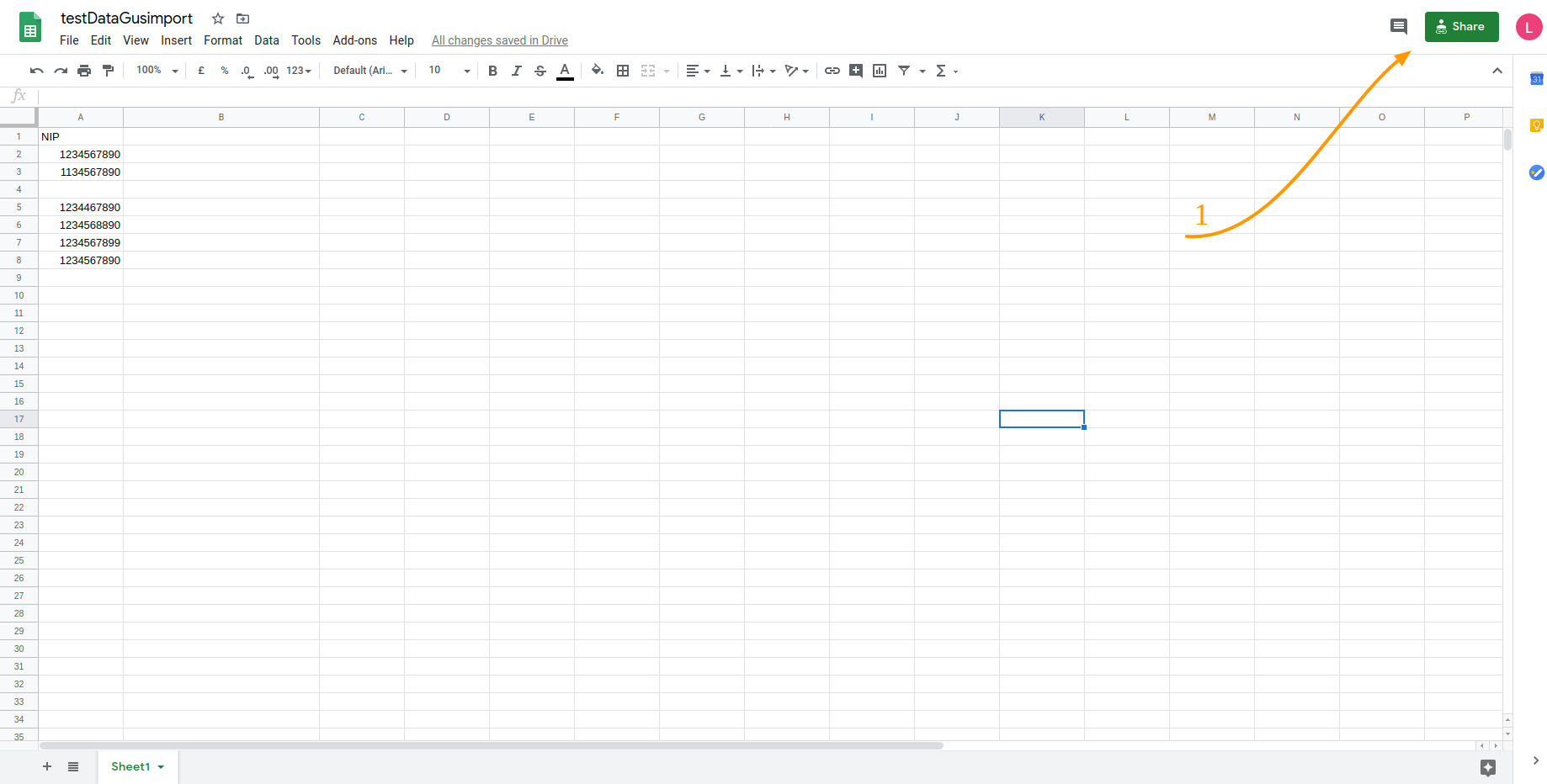
Rysunek 3.5 przedstawia przygotowany arkusz google z danymi testowymi (wiersze, w których brakuje numeru nip zostaną odrzucone przez analizę). Aby umożliwić czytanie pliku aplikacji, należy kliknąć zaznaczony na rys 3.5 punktem 1 przycisk “Share”. Następnie kliknąć opcję ”Get shareable link” (rys 3.6), aby udostępnić i skopiować link do arkusza.

3.3.4 Zatwierdzenie konfiguracji.
Każdorazowo po wprowadzeniu zmian w konfiguracji należy zapisać nowe ustawienia klawiszem “Zapisz”. W przypadku pliku CSV oraz pliku google istnieje również opcja zapisania i załadowania danych w celu weryfikacji podanej ścieżki i innych ustawień. “Zapisz i załaduj dane” (rys 3.3 pkt 5 oraz rys 3.4 pkt 4) skutkuje wprowadzeniem nowych danych do bufora.
UWAGA: jeżeli w konfiguracji będzie zaznaczona opcja czyszczenia bufora, nastąpi to za każdym razem przy wczytywaniu danych. Oznacza to, że każdorazowo wszelkie zmiany dokonane na danych zaczytanych będą nadpisywane przez dane z pliku.
3.3.5 Jednorazowe wczytanie danych z pliku.
Aby jednorazowo wczytać dane z pliku, a następnie modyfikować je już wewnątrz modułu automatycznej weryfikacji NRB, należy:
– skonfigurować prawidłowo pobieranie danych z pliku zdalnego csv lub z arkusza google i zapisać dane klikając “Zapisz i załaduj dane”,
– sprawdzić dane wczytane do bufora analiz,
– ponownie skonfigurować zdalne pobieranie danych jako “Automatyczny import wyłączony”,
– zapisać zmiany.
W ten sposób będziemy mieć zaczytane dane z pliku bez opcji ich nadpisywania z pliku, a analizie będzie poddawany tylko pierwotnie dodany zbiór uwzględniający zmiany wprowadzone ręcznie.
3.4. Wprowadzanie danych do analizy pojedynczo.
Aby móc dodawać dane ręcznie, rekord po rekordzie, należy w konfiguratorze wybrać i zapisać opcję “Automatyczny import wyłączony”. Przy takiej konfiguracji możliwe jest wprowadzanie i modyfikowanie zasobów znajdujących się w bazie automatycznych analiz.
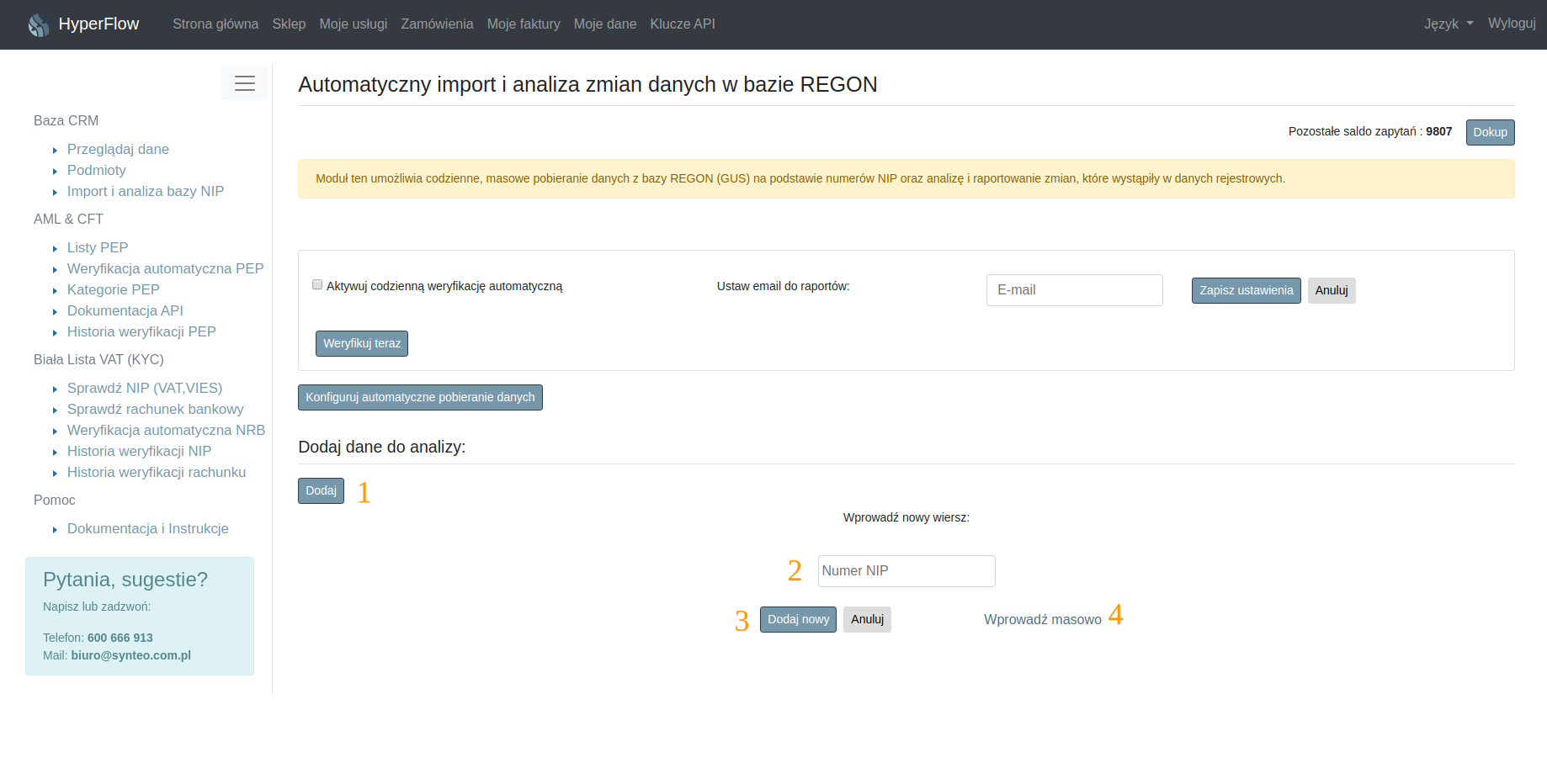
Aby dodać dane ręcznie: pojedynczo, masowo, lub z pliku csv z komputera, należy kliknąć przycisk “Dodaj” – punkt 1 na rysunku nr 3.7. Ręczne wprowadzanie danych odbywa się poprzez wprowadzenie numeru NIP i zatwierdzenie przyciskiem “Dodaj nowy”.
Drugim sposobem wprowadzania danych jest wprowadzanie masowe z pliku CSV lub za pomocą listy. W tym celu należy przejść do wprowadzania masowego danych (punkt 4 rys 3.7).
3.5. Ręczne masowe wprowadzanie zbioru danych.
Masowe wprowadzanie danych z pliku lub za pomocą wklejenia zbioru danych umożliwia widok przedstawiony na rys 3.8.
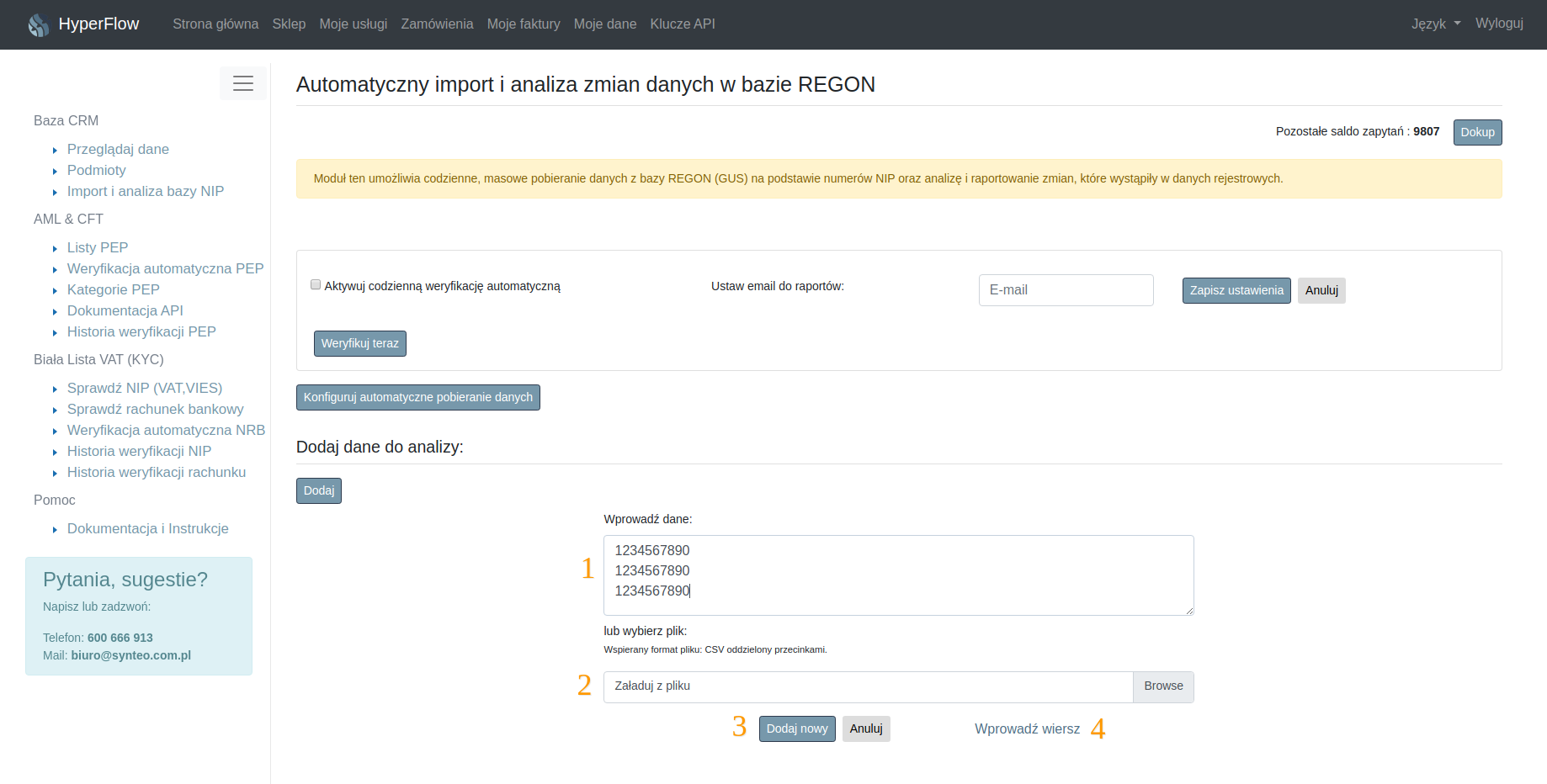
Numerem 1 na rysunku zostało oznaczone okno wprowadzania danych. Rozmiar okna dialogowego do masowej weryfikacji może być dostosowany za pomocą prawego dolnego rogu tego okna.
Nr 2 na rysunku to pole przeglądarki plików. Umożliwia ono zaczytanie danych z pliku CSV. Odpowiednio przygotowany plik w formacie csv, w którym pierwszą kolumnę stanowią numery NIP należy znaleźć przez wyszukiwarkę, a następnie kliknąć “OPEN”/”OTWÓRZ”. Po tej operacji należy kliknąć na panelu “Dodaj nowy” (rysunek 3.8. pkt 3). Plik zaczyta się automatycznie do analiz. Przed kolejną próbą wprowadzenia danych za pomocą okna wprowadzania danych należy odświeżyć stronę, aby upewnić się, że wprowadzony plik nie jest dłużej podłączony.
Nr 4 na rysunku 3.8 to powrót do okna pojedynczego wprowadzania danych.
3.6. Modyfikacja danych w analizach.
Jeżeli bufor danych nie jest pusty, na panelu modułu będą dostępne statystyki (rys 3.9 pkt 1) dla wprowadzonych danych oraz wyniki ostatniej analizy. Jeżeli dane zostały wprowadzone, jednak nie były jeszcze poddane analizie, będą posiadały one status “Oczekujący”. Jeżeli konfigurator jest ustawiony jako “Automatyczny import wyłączony”, możemy modyfikować zbiór danych jakie poddawane będą analizie (punkt 3 i 4 rys 3.9 ).
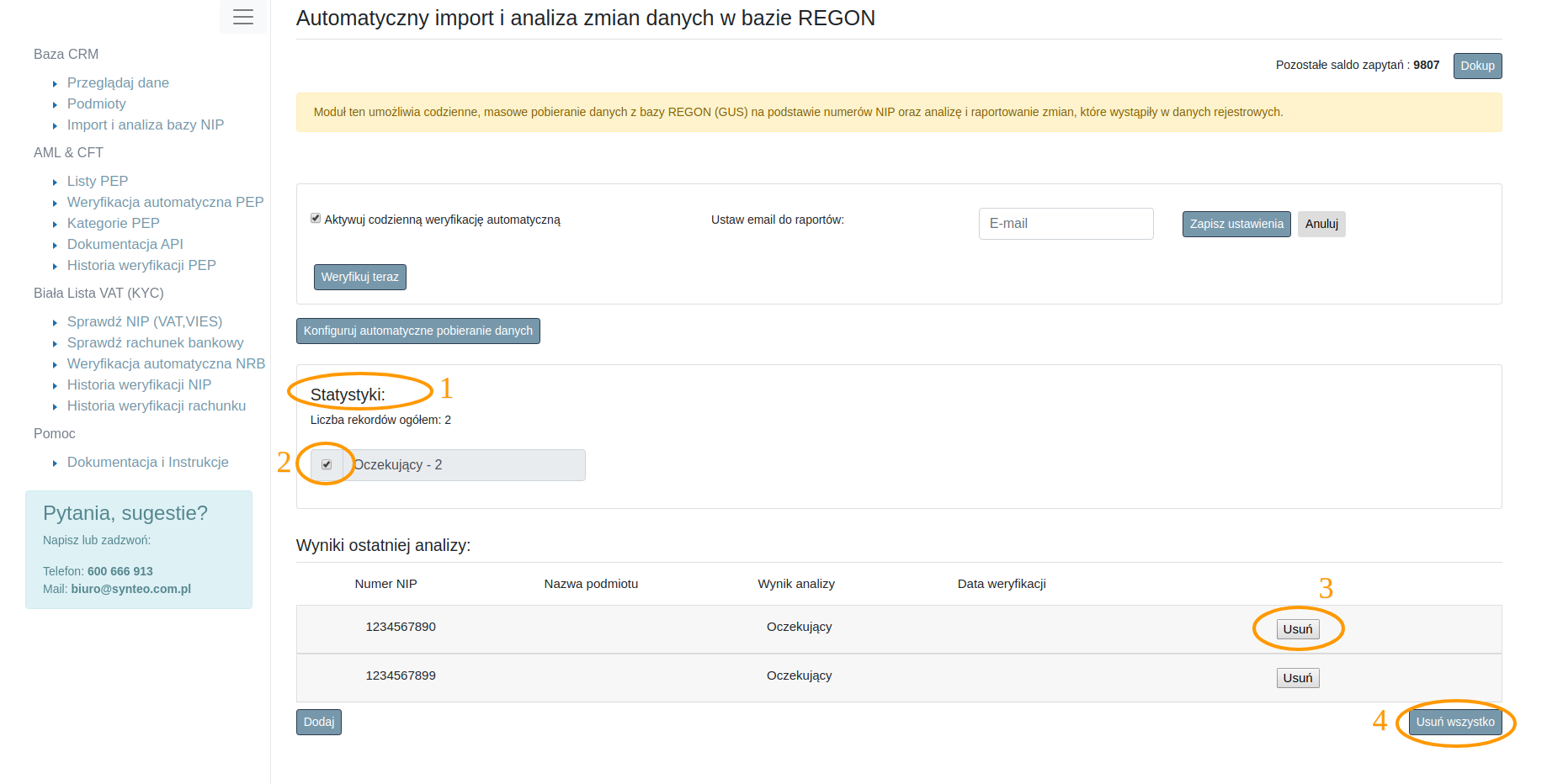
Na rysunku nr 3.9 punktem 2 został zaznaczony checkbox umożliwiający filtrowanie wyników analizy. Jeżeli dane były poddane analizie, statystyki w łatwy sposób pozwolą filtrować rekordy z różnymi statusami weryfikacji.
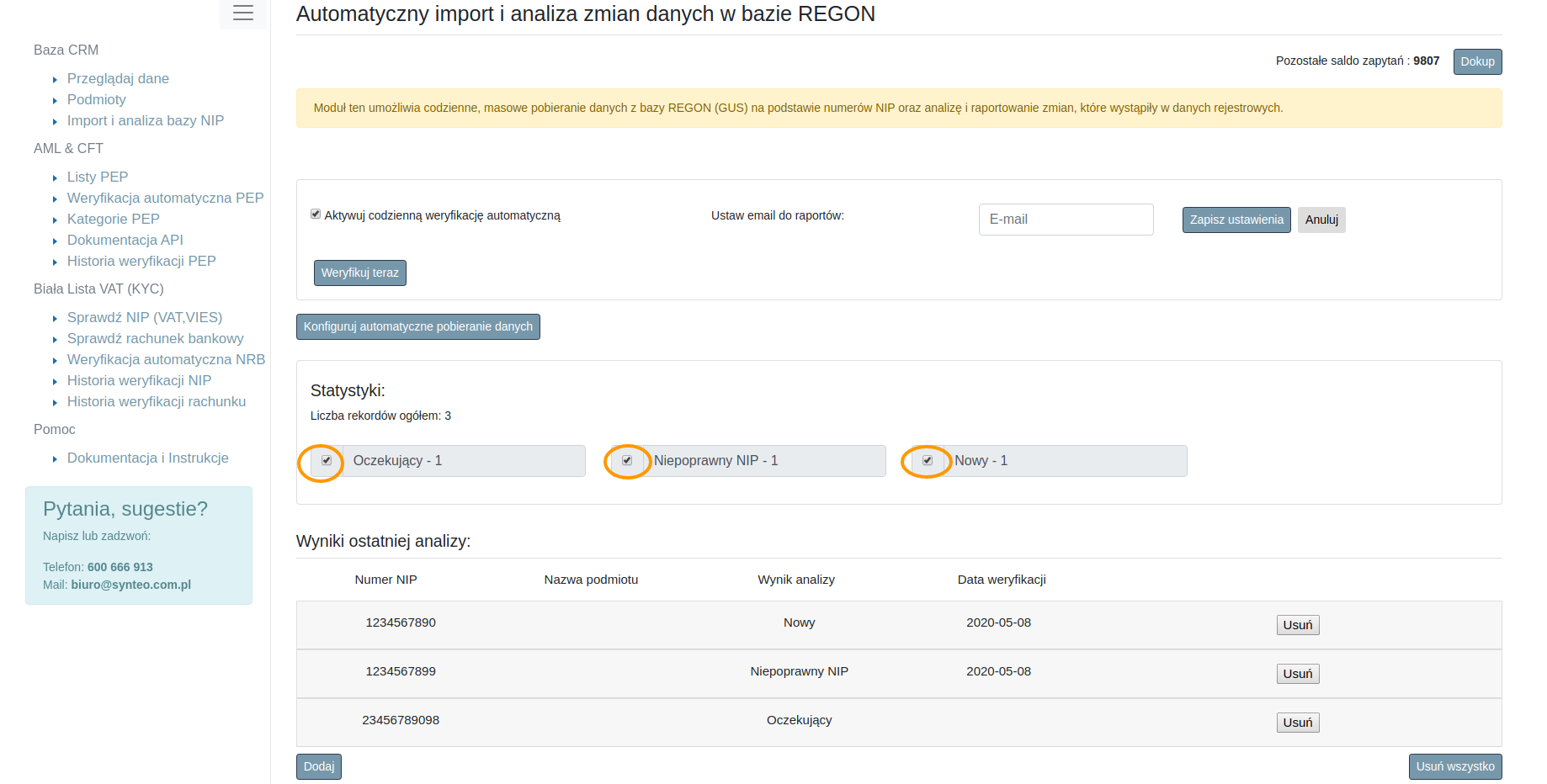
Na rysunku 3.10 zostały oznaczone opcje filtrowania danych za pomocą statystyk. Odznaczenie jednego lub kilku rodzajów statusów pozwala na szybkie odnalezienie i przeglądanie interesującego nas zakresu danych. W części “Wyniki ostatniej analizy” znajdują się dane dla każdego rekordu w postaci wyniku analizy oraz daty dokonania analizy.
Więcej informacji: https://nip.waw.pl